You can see this problem in the search filter in Safari.
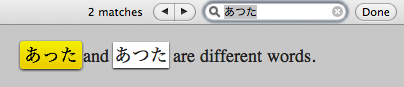
Because WebKit uses ICU for searching. ICU has a very strict implementation of the Unicode Collation Algorithm. Therefore this problem is reproducible in Safari.
In the current Unicode Collation Algorithm, っ (U+3063) is considered as a small form of つ (U+3064).
Then, these characters are treated as the same just like a and A in the primary strength and in the secondary strength.
But in Japanese semantics, っ (U+3063) and つ (U+3064) should be always treated as different characters even in a case insensitive context.
As you know in English, abc and ABC are treated as the same in a case insensitive context.
But in Japanese, for example, あった and あつた are different words in any contexts. Because in Japanese semantics, っ is not considered as a small form of つ. These characters are never treated as the same characters.
In the current Unicode Collation Algorithm, the character pairs in the following list are treated as the same in the primary strength and in the secondary strength. But these character pairs should be always treated as different characters.
| あ (U+3042) | ぁ (U+3041) |
| い (U+3044) | ぃ (U+3043) |
| う (U+3046) | ぅ (U+3045) |
| え (U+3048) | ぇ (U+3047) |
| お (U+304A) | ぉ (U+3049) |
| か (U+304B) | ゕ (U+3095) |
| け (U+3051) | ゖ (U+3096) |
| つ (U+3064) | っ (U+3063) |
| や (U+3084) | ゃ (U+3083) |
| ゆ (U+3086) | ゅ (U+3085) |
| よ (U+3088) | ょ (U+3087) |
| わ (U+308F) | ゎ (U+308E) |
| ア (U+30A2) | ァ (U+30A1) |
| イ (U+30A4) | ィ (U+30A3) |
| ウ (U+30A6) | ゥ (U+30A5) |
| エ (U+30A8) | ェ (U+30A7) |
| オ (U+30AA) | ォ (U+30A9) |
| カ (U+30AB) | ヵ (U+30F5) |
| ケ (U+30B1) | ヶ (U+30F6) |
| ツ (U+30C4) | ッ (U+30C3) |
| ヤ (U+30E4) | ャ (U+30E3) |
| ユ (U+30E6) | ュ (U+30E5) |
| ヨ (U+30E8) | ョ (U+30E7) |
| ワ (U+30EF) | ヮ (U+30EE) |
| ア (U+FF71) | ァ (U+FF67) |
| イ (U+FF72) | ィ (U+FF68) |
| ウ (U+FF73) | ゥ (U+FF69) |
| エ (U+FF74) | ェ (U+FF6A) |
| オ (U+FF75) | ォ (U+FF6B) |
| ヤ (U+FF94) | ャ (U+FF6C) |
| ユ (U+FF95) | ュ (U+FF6D) |
| ヨ (U+FF96) | ョ (U+FF6E) |
You can see this problem in the search filter in Safari.
Because WebKit uses ICU for searching. ICU has a very strict implementation of the Unicode Collation Algorithm. Therefore this problem is reproducible in Safari.